🎙 FoC #65 Interpreting the Rule(s) of Code 💡 Freewheeling Apps 🧘 Calm Tech
Two Minute Week
🎥 Adding eval and supercompilation via Peter Saxton
🧵 conversation
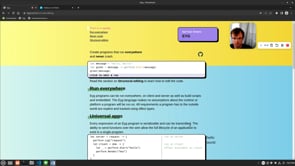
I've added eval to my language in the last week. Trying to get my head around supercompilation so I can precompute terms that are evaled and then have typesafe string.format Does any language make use of this eval at compiletime to reduce untypable functions, like eval.
Our Work
🎙 Future of Coding #65 Laurence Diver • Interpreting the Rule(s) of Code: Performance, Performativity, and Production via Ivan Reese
🧵 conversation
The execution of code, by its very nature, creates the conditions of a “strong legalism” in which you must unquestioningly obey laws produced without your say, invisibly, with no chance for appeal. This is a wild idea; today’s essay is packed with them. In drawing parallels between law and computing, it gives us a new skepticism about software and the effect it has on the world. It’s also full of challenges and benchmarks and ideas for ways that code can be reimagined. The conclusion of the essay is flush with inspiration, and the references are stellar. So while it might not look it at first, this is one of the most powerful works of FoC we’ve read.
📝 A 3D operating system without apps via Duncan Cragg
🧵 conversation
Freeing our digital stuff from the "app trap"!
Hiya - I've got a new article in my Object Network "Lab Notes" Substack
💡🎥 Hands-on with Freewheeling Apps via Kartik Agaram
🧵 conversation
A 20-minute video on my lived experience with Freewheeling Apps
💻 author.quickpoint.me via greg kavanagh
🧵 conversation
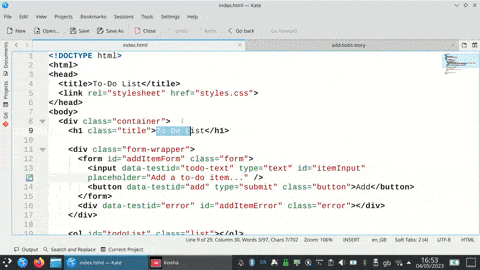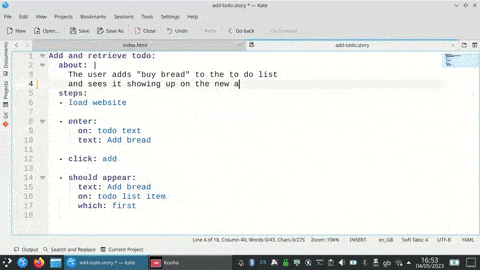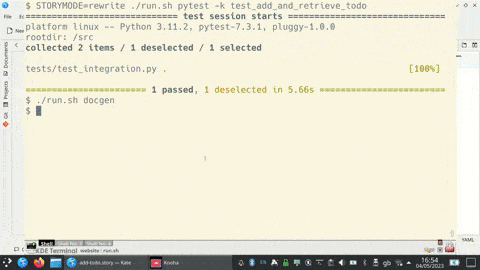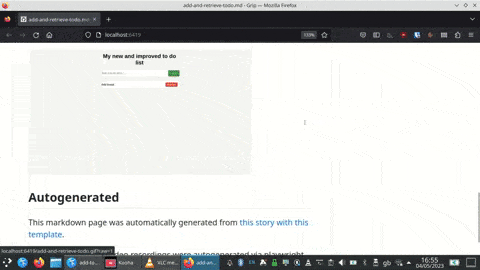
I’ve been working on a DSL for creating mixed media pages. Markdown meets YAML and we’re about to hire some real designers to make it look normal… however if anyone would like to play with it while it’s weird and wonky you can check it out at author.quickpoint.me
📝 How to design a CLI via Tyler Adams
🧵 conversation
I'm restarting my programming productivity blog, here's the latest on CLI tool design
Vercel’s a got a great system for deploying serverless JS web apps. It Just Works(TM). Vercel’s CLI however…is a learning example. We’ll go over some of their interesting and noteworthy design choices, and then, describe what other option we could take.
Devlog Together
💬 Jason Morris
🧵 conversation
Doesn't look like much. But under the hood it's a demo of an LLM-powered langchain agent using my Blawx software's public API to generate an answer based on a human-validated symbolic encoding, fully explainable with reference to source materials, and zero risk of hallucination. All of the usability upside of ChatGPT, none of the opacity and horseshit. It BARELY works with 3.5-turbo, some of the time. I need GPT4 API access to really generalize it, in addition to a few changes to Blawx to add natural language meta-data that can be used in prompts. If anyone has any tips on how to get access to GPT4 faster without breaking any laws, that'd be great.
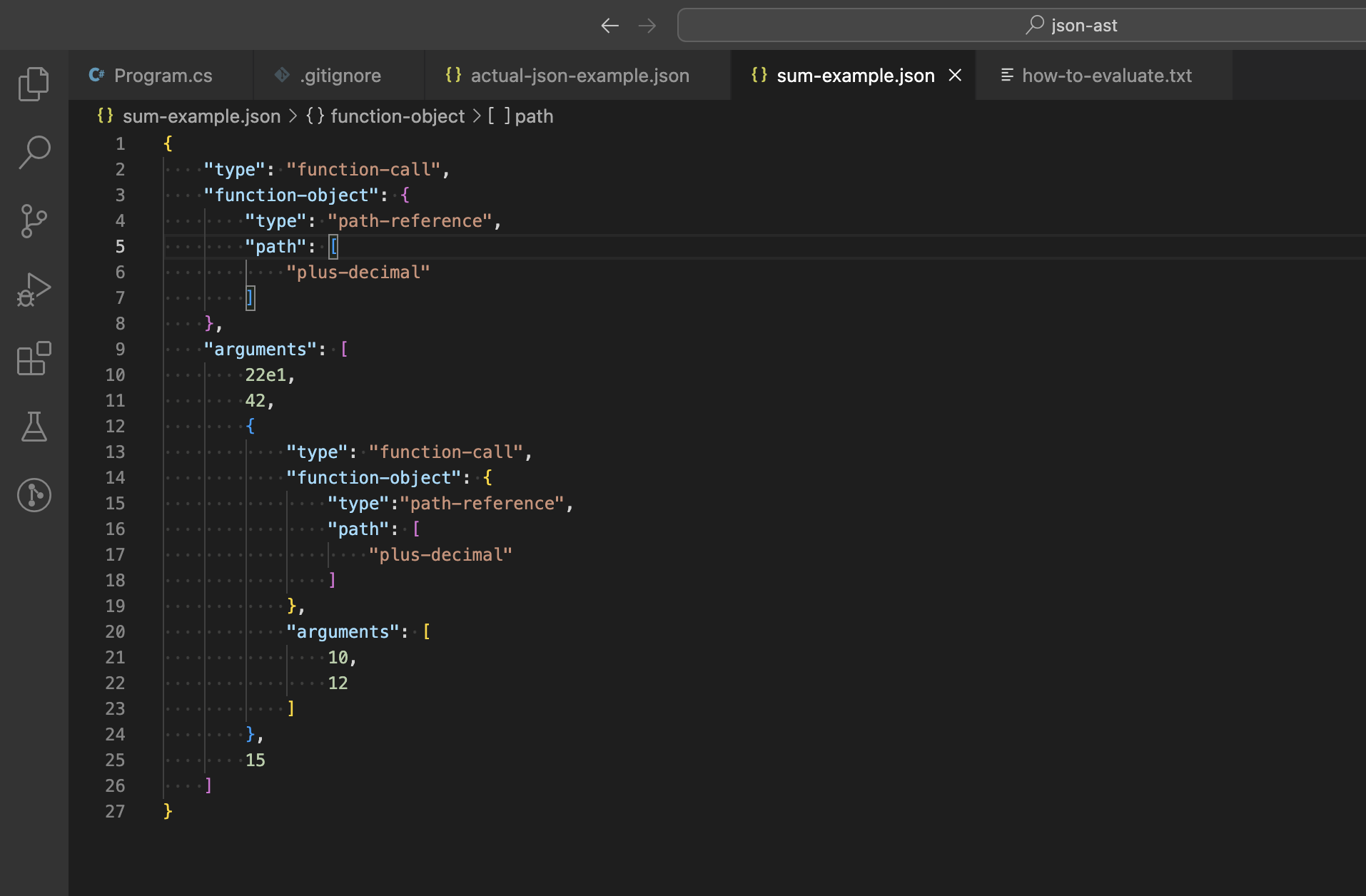
💬 Oleksandr Kryvonos
🧵 conversation
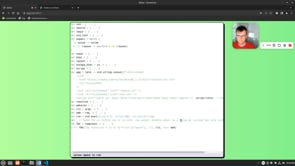
I am creating and interpreter for AST stored in JSON (see picture) (Lisp-idea--style) and I am playing with partial & reactive evaluation (Excel--style) for it
Reading Together
📝 Myths and Mythconceptions: What does it mean to be a programming language, anyhow? via Srini K
🧵 conversation
Enjoying this read, love the term “vernacular programmer”
Thinking Together
💬 Duncan Cragg
🧵 conversation
Dynamicland could be done better with Augmented Reality specs. All that frayable, water- and fire-damageable stuff. No version control? No backups? Those little test tube doodads will fall apart after a few months. Plus with AR you can actually use that amazing innovation they call the Inter Network. Argue away, humiliate me for my lack of Bret Victor worship!
📝 System and method for combining text editing and tree encoding for computer programs via Jarno Montonen
🧵 conversation
I run into this fairly recent (sent 2017) patent that seems to just describe an incremental parser which is used to 'enrich' textual program code with syntactic and semantic annotations. I don't really understand what the patent tries to protect and what is supposed to be the patent worthy invention here as for example tree-sitter existed in 2017 already. I'd be interested to hear any thoughts on this.
💬 Hamish Todd
🧵 conversation
I'm interested in the concept of a "spread", which I have seen discussed by Toby Schachman and Joshua Horowitz partly in the context of dynamicland, though I forget where, anyone got a link? In my own system, I'm thinking I'll have them.
📝 Save Your Twitter Likes Without Using the API via Sam Butler
🧵 conversation
I want to be able to post microblog style content, and have it cross-post to different platforms (e.g. Twitter, Mastodon, LinkedIn, Facebook) — in a way that is resilient to corporate api hijinx. (Perhaps aligned with the approach/philosophy of this project, getting into browser automation? mschmitt.org/blog/save-liked-tweets-without-twitter-api. Or this approach, based on local device automation?) I also think it would be cool to explore pulling content from multiple platforms and synthesizing them into a single alternative feed — sort of like an RSS for your Twitter, Facebook, LinkedIn, Mastodon, Reddit timelines. Again, in a way that is resilient to corporate api hijinx. Is anybody interested in exploring this? I would also be interested in low-energy and low-data/bandwidth approaches to doing this, because that's the world we're moving towards (hopefully)
💬 Eli Mellen
🧵 conversation
around these parts we talk a lot about the technical aspects of the future of coding — what are some of the social or cultural aspects of the future of coding folks see?
- See either holding us back from doing more future of coding flavored stuff out in the wild yonder
- Or see in the future, allowing for new sorts of stuff
📝 Debugging Lisp Part 4: Restarts - malisper.me via Tim Lavoie
🧵 conversation
Hi all. I just finished listening to the episode, "Interpreting the Rule(s) of Code by Laurence Diver". I wasn't sure it was going to hook me, but am so glad it did. I had a few thoughts bounce around as I was listening, though dog-walking on a trail. Hopefully they make some sense now.
Where Ivan was talking about the problem of a program only being able to handle conditions for which it was designed, with no escape hatch, I wondered about exposing something like the restarts that Common Lisp has in its REPL. This probably isn't something you would offer to a user that you didn't trust with a REPL, but perhaps encountering a problem could default to selections of alternate solutions that are offered to the user. When restarts are offered in CL, the program execution is paused, so the choices for the user have all the context of what is on the stack at the time. Rather than just aborting (which is one option), one might take an extra step back and try something different. Web checkouts typically have a weak form of this, but I thought that perhaps very binary conditional checks could often be replaced with "one of" or combinations of options. Don't have that right address? (RR 2, Pfff!). Include some other means of providing a location that is accepted. Maybe some form of fuzzy logic, albeit unfashionable these days, guides the programmer into accepting a combination of responses that satisfy their fraud-prevention algorithm when taken together.
malisper.me/debugging-lisp-part-4-restarts
Also, the whole concern makes me think of the eventual corporate destination, "Computer Says No" from Little Britain.
This is part four of Debugging Lisp. Here are the previous parts on recompilation, inspecting, and class redefinition. The next post on miscellaneous debugging techniques can be found here. Many languages provide error handling as two distinct parts, throw and catch. Throw is the part that detects something has gone wrong and in some way […]
🎥 Little Britain USA - Computer says no

💼 regular spreadsheet via Beni Cherniavsky-Paskin
🧵 conversation
Say, has anyone ever tried BASIC's non-consecutive numbers for spreadsheet coordinates?
We programmers always laugh at spreadsheet's use of coordinates ("like machine code without assembly") but few users avail themselves of features to name ranges / structured/hierarchical data etc.
But there are real annoyances with what-you-see-is-what-you count consecutive coordinates: They mostly shift correctly on insertions/deletions, BUT one needs to grok $A4 vs. B$7 notation, which I suspect many don't. Getting range E3:F34 boundaries for formulas exactly right is always a hassle.
So I wonder if features like named ranges are "premature formalization" then maybe "structured numbers" in the BASIC's style could serve as more accessible "semi-formalization"?
BASIC users quickly learnt conventions like "increment by 10, start functions on hundreds, big modules on thousands". And this allowed them to avoid re-numbering almost entirely!
(This was good UX in teletype line-editor era 🖨, and of course now we have full-screen editors and can insert/delete — no need to "increment from 10 to 20 so you can later insert 15".
But a 2nd aspect that imho was really genius was the numbers were stable , helping your brain 🚲🧠. Your transcript 📜 had partial LIST ings, followed by chains of edit actions (poor man's git) + REPL experiments, and the fact that line 60 remains 60 throught helped you mentally interpret that history — making you a better debugging detective 🕵️♀️. It's insane to remember what GOSUB 437 means; easier if you assign semi-systematic round GOSUB 2100 .)
So, suppose spreadsheets let you use higher numbers/column names freely, by skipping display of unoccupied rows/columns.
- If you have a long table that might grow, you won't put
=SUM(...) computation directly beneath it; you put it at next 100 or 1000 — but it will still display close to its bottom. And you can type the range as 10:99 from the start.
- With some foresight allocating "big enough" ranges for tables, you might never run into situations where
$B7 vs. B$7 matters. (This means spreadsheet should become smarter yet in renumbering on insert/delete — do shift rows/columns, but stop at next unoccopied "moat".)
- To introduce users to the idea, don't show consecutive numbers/letters. Even in an empty spreadsheet, after some rows/columns, skip to some far-away numbers like 100 and 1000!
- Perhaps it might also subsume the feature of "freezing" some rows/column from scrolling? mockup below has one fake "scrollbar" to suggest a portion could be scrolled separately.
attaching a mockup to this thread (drawn in a regular spreadsheet😉)
🧘 calmtech.com via Martin Shaw
🧵 conversation
Been reading a lot about Calm Tech (calmtech.com), technology designed to require a minimum of the user's repeated attention. Products/projects which make information available to the user on the user's request and not the other way around.
As someone who has wasted plenty of time on social media, I find the design ideas fleshed out on the site and related projects fascinating. Does anyone else have an interest? Seems like a positive (for once) way 'back to the future' of useful home-based tech.
💬 Martin Shaw
🧵 conversation
I know that it doesn't necessarily implement many of the points from the 'manifesto' and televisions are still attention sinks, but I always thought that the Samsung 'The Frame' TV was interesting because it move the centerpiece of the lounge from a big, cold, out-of-place television to an inquisitive wall of artwork until the user chooses that they want to watch television.
💬 Ivan Reese
🧵 conversation
I'm suddenly bothered by the fact that code comments are always the same size .
Sure, I've seen some people play with rich text in their code editor, applying bold or font size the same way you apply color. Atom's CSS was great. But that's outside the code. Your font size tweaks aren't going in the repo. (That'd be a tabs vs spaces fight for the ages!)
But… what if I want to leave a little pocketbook tucked into the back flap of a function? Unobtrusive. It's there as a reference when you need it. Within, you can fully explain why things are the way they are. You can talk about the history of this code. It's the sort of stuff that you'd put into a wiki, or spread across a series of commit messages — but it's right there in the codebase, but it's tiny and off to the side. There when you need it, easy to ignore when you don't.
Makes me wonder about other ways that being able to choose the size of representation in a program — independently from typical size units of code (ie: lines) — could be useful. Eg: at the main entry point of a well-factored complex program, where you're dispatching off to various other subsystems, things deserve to be quite large.
Makes me wonder about other things that ought to live inside the codebase. To start: every feature of Github? (Consider that it serves their interests that, say, the discussion around an issue or PR lives on their cloud, not in the repo.)
💬 Grant Forrest
🧵 conversation
Only halfway through the latest podcast ep but my imagination is piqued. Is there a version of, like, unit testing, where the software generates some randomized states based on its internal state and unknown inputs, presents the outcome as part of a report, and asks humans to correct any erroneous assumptions or missing contingencies? IDK how to even describe what I'm thinking of but I feel like it must exist, or maybe be theoretical in the emerging AI models of creating software.
Kind of fuzz testing, I guess. My brain is going somewhere bigger with this, though, maybe I'll check in with it again once I find time to finish the podcast.
🧵 conversation
Another thing. My wife worked at a legal research company for a while and she kept pausing the podcast (I subjected her to) to comment on the legal side of things. One thing she pointed out is that civil law is about codifying and interpreting laws to judge situations, but common law is basically a series of precedents. You try a case, if it's novel you invent a judgment. If it's similar to a previous case you adopt/adapt the previous judgment and it becomes a new more refined precedent for future situations.
Not sure the mapping here. I'm imagining when Ivan puts in his address to buy a ticket, instead of "invalid address" and end of story, the software responds, "this format of address is new to us, please await trial" and forwards it to the Airline Judge who renders judgment that is then encoded as precedent in the software itself.
Content
🖊️ An update on Dynamicland via Ivan Reese
🧵 conversation
📝 Bad software sent postal workers to jail, because no one wanted to admit it could be wrong via Ivan Reese
🧵 conversation
Something something ruleishness something something legalism something something
(Via Kartik Agaram)
The software was used as evidence that employees stole money
📝 The Development of the C Language - Dennis M. Ritchie via Shubhadeep Roychowdhury
🧵 conversation