✉️ Not subscribed yet? Subscribe to the Newsletter
Future of Coding Weekly 2023/08 Week 3
2023-08-27 18:50
🤔 Backends at any scale in 100x less code 🎥 Unit by Samuel Timbó
Devlog Together
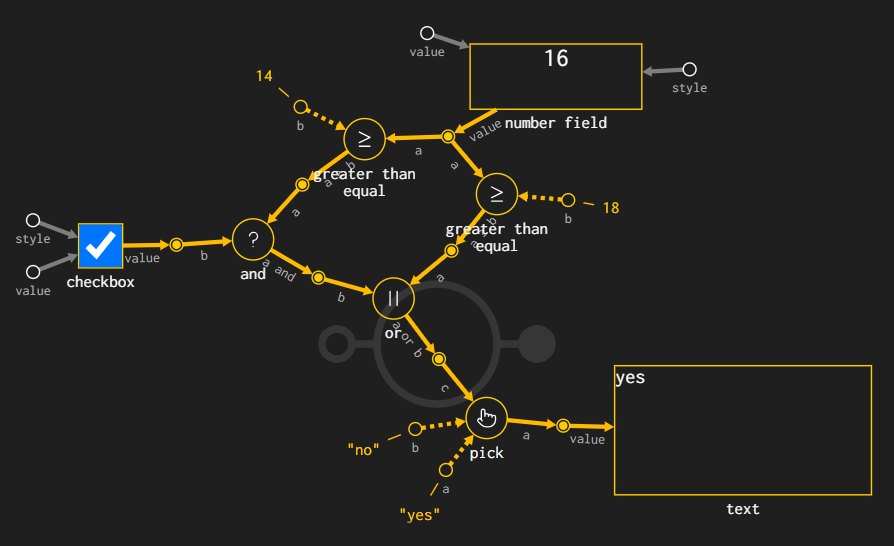
A little bit of Rules as Code in Unit: "a person can write a will if they are 18 or at least 14 and in the military". The checkbox indicates if they are military, the number field is their age, and the text field is the answer to whether they can write a will. What's interesting is that the diagram illustrates the reasons. If they qualify both ways, both paths are yellow.
Reading Together
📝 “Myths and Mythconceptions: What does it mean to be a programming language, anyhow?” by Mary Shaw (2021) via Christopher Shank
Content
🤔 How we reduced the cost of building Twitter at Twitter-scale by 100x via Mariano Guerra
How we reduced the cost of building Twitter at Twitter-scale by 100x
Rama unifies computation and storage into a coherent model capable of building end-to-end backends at any scale in 100x less code than otherwise. Rama integrates and generalizes data ingestion, processing, indexing, and querying.
I’m going to cover a lot of ground in this post, so here’s the TLDR: We built a Twitter-scale Mastodon instance from scratch in only 10k lines of code. This is 100x less code than the ~1M lines Twi…
🎥 Flowistry - Helping Rust Developers See Data Dependencies in the IDE (Will Crichton, August 2023) via Cole Lawrence

I just finished editing and published the talk from Rust East Coast. Perhaps some programming theory folks could find it interesting! cc Garth Goldwater
In a large Rust codebase, it can be difficult to find just the code you need to implement a feature or fix a bug. This talk will introduce Flowistry, a tool for visualizing data dependencies in Rust programs that can help programmers quickly sort out irrelevant code. I will explain what makes static analysis of dependencies a difficult problem, and I will describe the key insight in Flowistry that makes the problem tractable.
Presented by Will Crichton
📝 Introduction: Situating Critical Code Studies in the Digital Humanities via Eli Mellen
Introduction: Situating Critical Code Studies in the Digital Humanities
Critical code studies is the application of the hermeneutics of the humanities to the interpretation of the extra-functional significance of computer source code. “Extra” here does not mean “outside of” or “apart from” but instead it refers to a significance that is “growing out of” an understanding of the functioning of the code.
This piece also links to a few other interesting resources on the subject, including, the initial manifesto for critical code studies.
I also liked this quote,
Still, reading code, even without interpreting its cultural significance, can be no easy task. Ask a professional programmer who inherits legacy code to maintain or, worse yet, to improve, and they will tell you about the dread of sorting out just-in-time code, minimally documented, written with hasty patches, full of compromises and workarounds. Even those who write their code in artistic projects can be shy about sharing their code out of embarrassment and self-consciousness. This shame is a product of the “encoded chauvinism” of programming culture, one that can be fostered on the internet as much as it is in classrooms
Marino 2020
📝 The Critical Carbon Computing Collective’s issue of Branch is out! via Eli Mellen
🎥 Unit by Samuel Timbó via Ivan Reese
Today's workshop on Unit with @Samuel Timbó is now up on YouTube
Thanks to everyone who attended, and to Sam for building and demoing such an impressive piece of tech!
📝 some writers use an old word processor called WordStar via David Alan Hjelle
I thought this article on why some writers use an old word processor called WordStar was interesting. I wonder if there are any implications here for editing programs? Some of the ideas — like comments — we usually take for granted in programming. But maybe there are some other worth-while take-aways?
Let me speak generally for a moment. I've concluded that there are two basic metaphors for pre-computer writing. One is the long-hand manuscript page. The other is the typewritten page. Most word processors have decided to emulate the second — and, at first glance, that would seem to be the logical one to adopt. But, as a creative writer, I am convinced that the long-hand page is the better metaphor.
Consider: On a long-hand page, you can jump back and forth in your document with ease. You can put in bookmarks, either actual paper ones, or just fingers slipped into the middle of the manuscript stack. You can annotate the manuscript for yourself with comments like "Fix this!" or "Don't forget to check these facts" without there being any possibility of you missing them when you next work on the document. And you can mark a block, either by circling it with your pen, or by physically cutting it out, without necessarily having to do anything with it right away. The entire document is your workspace.
On a typewritten page, on the other hand, you are forced to deal with the next sequential character. Your thoughts are focussed serially on the typing of the document. If you're in the middle of a line halfway down page 7, your only easy option is to continue on that line. To go backwards to check something is difficult, to put in a comment that won't show when your document is read by somebody else is impossible, and so on. Typing is a top-down, linear process, not at all conducive to the intuitive, leaping-here-and-there kind of thought human beings are good at.
Anyone ever played with Symboleo? I'm only now learning it is under development in Canada (University of Ottawa) for use in legal contracts. Logic based, uses event calculus, implemented in Prolog-inside-Java, looks like. Shares a lot of design objectives with what I'm doing with Blawx.
📝 Scratch via Shalabh Chaturvedi
I’ve been doing Scratch with kids recently and while it’s fun, I’m looking for something next level. Specifically things like no shared custom blocks across sprites is becoming problematic (copy paste issues). Any recommendations?